
Android Handler 原理分析
Handler 是 Android 应用非常重要的组成部分,它的身影可谓是无处不在了,从系统源码到第三方库,再到我们开发的过程中都离不开 Handler。许多开发中的问题也涉及到 Handler 相关的知识,例如 ANR 问题、UI 的绘制以及线程的调度等,本文将从源码分析、常见问题以及 Handler 的一些应用等方面进行分析。
Handler 原理分析
什么是 Handler
下边是官网对于 Handler 的定义
A Handler allows you to send and process Message and Runnable objects associated with a thread’s MessageQueue. Each Handler instance is associated with a single thread and that thread’s message queue. When you create a new Handler it is bound to a Looper. It will deliver messages and runnables to that Looper’s message queue and execute them on that Looper’s thread.
其大概意思就是说,Handler 可以发送 Message 或 Runnable 到消息队列(MessageQueue)中,每一个 Handler 实例和一个线程及这个线程的消息队列相关联。创建一个 Handler 实例时需要和一个 Looper 进行绑定,它向这个 Looper 所在的线程的消息队列发送消息,并在当前的线程处理这些消息。
Handler 工作流程
Handler 的工作流程如下图所示: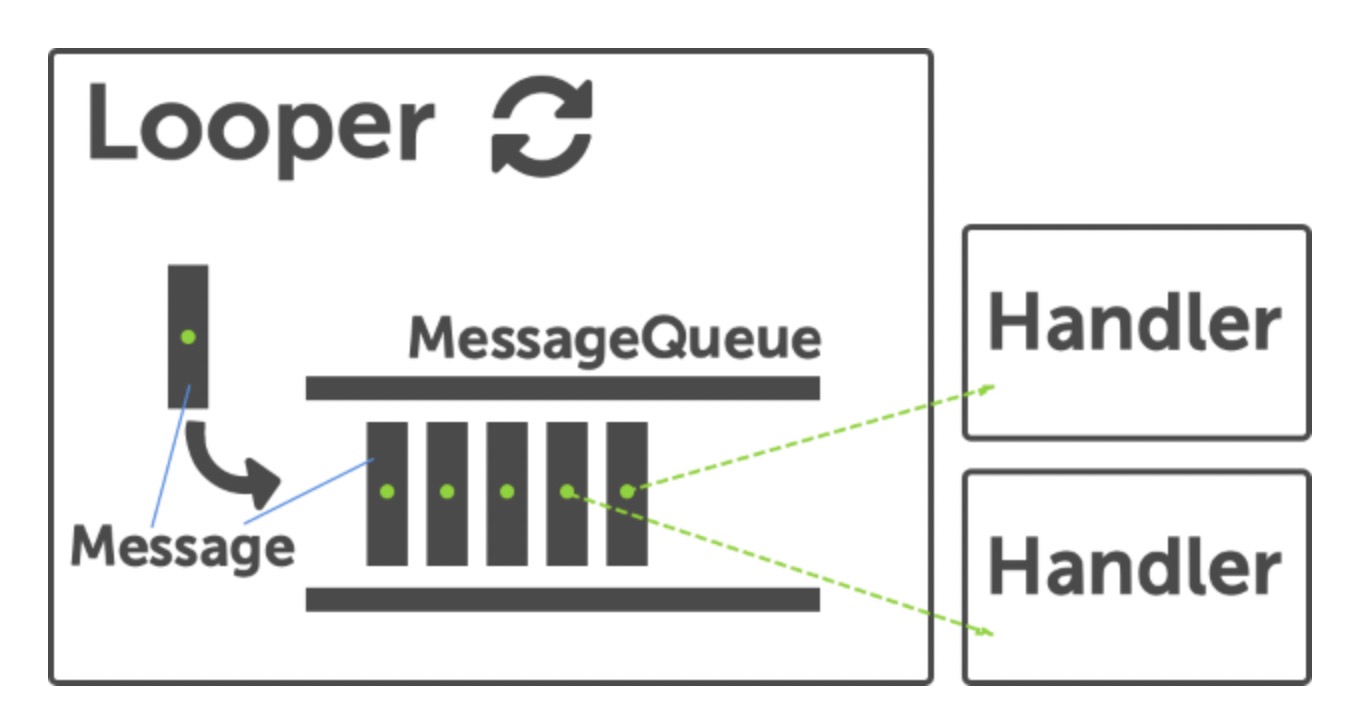
我们可以看出,Looper 为消息队列提供动力,不断地循环消息队列中的消息,Handler 向消息队列发送消息并处理消息。
Handler 关键方法调用如下所示: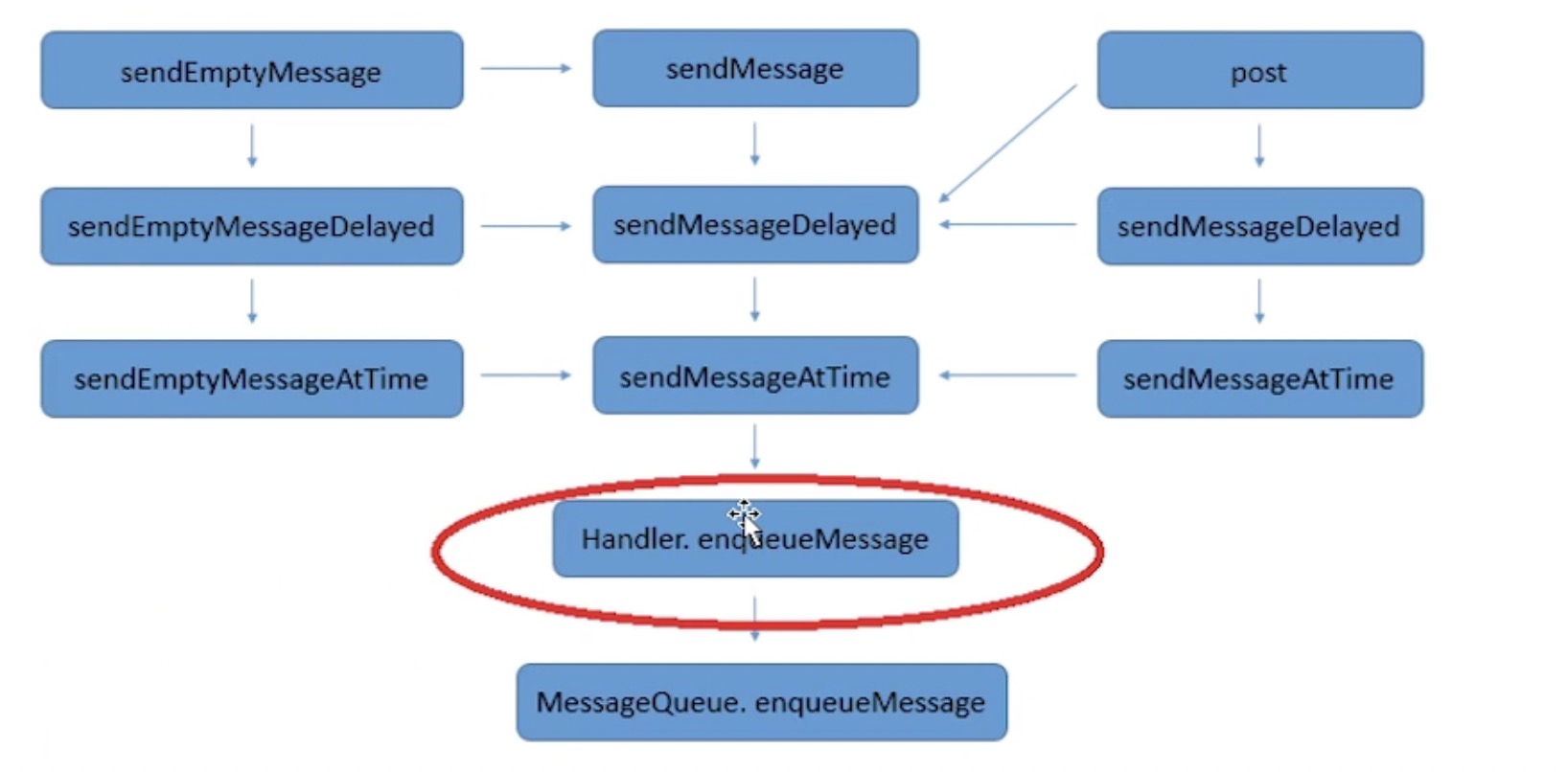
Android 主线程中的 Handler
从官网定义中,我们得知创建一个 Handler 实例时需要和一个 Looper 进行绑定,那么我们在平常使用 Handler 时并没有接触过 Looper 这个东西,这是因为在主线程创建 Handler 之前,Android 已经创建了一个 Looper 并开启了循环。我们可以看下应用的入口 ActivityThread.main() 方法:
// ActivityThread.java |
Looper.prepare()
首先调用了 Looper.prepareMainLooper() 方法:
public final class Looper { |
在 Looper.prepareMainLooper() 方法中又调用了 prepare() 方法,这个方法会创建一个 Looper,然后将这个 Looper 放到一个 ThreadLocal 中,并且在之前还进行了防止重复的校验。也就是说一个线程都有自己单独的 Looper,且只能创建一次。
然后再跟进到 Looper 的构造方法看一下:
// Looper.java |
Looper 在创建的时候也创建了消息队列,也就是说每一个线程中只能有一个 Looper 和 MessageQueue。
ActivityThread.H
我们再来看一下 ActivityThread 中的 sMainThreadHandler = thread.getHandler(); 这行代码,thread.getHandler() 实际上是获取的 ActivityThread 中的内部类 mH,这个 Handler 负责处理四大组件以及 Application 的一些消息。
//ActivityThread.java |
Looper.loop()
最后我们再看一下 Looper.loop() 方法:
// Looper.java |
在 loop 方法中是一个死循环,在这里从消息队列中不断的获取消息 queue.next(),然后通过 Handler.dispatchMessage() 进行消息的分发,其实并没有什么具体的绑定,因为 Handler 在每个线程中对应只有一个 Looper 和消息队列 MessageQueue,自然要靠它来处理,也就是是调用 Looper.loop() 方法。在 Looper.loop() 的死循环中不断的取消息,最后回收复用。
这里注意 Message 中的 target(Handler) 这个成员变量,正是有了这个变量,每个 Message 才能找到它所对应的 Handler,让多个 Handler 同时工作处理各自的消息
注意:在创建 Message 时,应该使用 Message.obtain() 方法创建,这样所有的消息会被回收,放入 sPool 中,使用享元设计模式。
Looper 死循环会消耗大量的资源吗?
关键就在 queue.next() 消息队列取消息的地方
// MessageQueue.java |
在 MessageQueue.next() 方法中,会调用 nativePollOnce() 本地方法,这里会利用 Linux 的 pipe/epoll 机制,在没有消息的时候阻塞在这里,此时主线程会释放 CPU 资源进入休眠状态,直到下个消息到达或者有事务发生,通过往 pipe 管道写端写入数据来唤醒主线程工作。
这里采用的 epoll 机制,是一种 IO 多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质同步 I/O,即读写是阻塞的。 所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量 CPU 资源。
关于 Linux 的 pipe/epoll 机制,可移步此文。
nativePollOnce()
// android_os_MessageQueue.cpp |
// Looper.cpp |
主线程的 Handler 的退出
在 App 退出时,ActivityThread 中的 mH(Handler)收到消息后,执行退出。
// ActivityThread.H.handleMessage() |
注意:当我们尝试手动退出时会抛出如下异常,这是因为主线程不允许退出,一旦退出就意味着程序挂了,退出也不应该用这种方式退出。
Caused by: java.lang.IllegalStateException: Main thread not allowed to quit. |
关于 ThreadLocal
从 Looper 的源码中,我们可以看到创建 Looper 实例后,将它放到了 ThreadLocal 中,以保证线程中各自都有一个 Looper 实例。
ThreadLocal 为每个线程都提供了变量的副本,使得每个线程在某一时间访问到的并非同一个对象,这样就隔离了多个线程对数据的数据共享。
ThreadLocal 原理
Java 的实现里面有一个 Map,叫做 ThreadLocalMap,持有 ThreadLocalMap 的是 Thread。Thread 这个类内部有一个私有属性 threadLocals,其类型就是 ThreadLocalMap,ThreadLocalMap 的 Key 是 ThreadLocal。
public class Thread implements Runnable { |
在 Java 的实现方案中,ThreadLocal 仅仅只是一个代理工具类,内部并不持有任何线程相关的数据,所有和线程相关的数据都存储在 Thread 里面,这样的设计从数据的亲缘性上来讲,ThreadLocalMap 属于 Thread 也更加合理。所以 ThreadLocal 的 get() 方法,其实就是拿到每个线程独有的 ThreadLocalMap。
这种设计方案的好处就是不容易产生内存泄漏,如果在 ThreadLocal 用一个键为 Thread 值为存储的内容的 Map 这种设计方案,ThreadLocal 持有的 Map 会持有 Thread 对象的引用,这就意味着只要 ThreadLocal 对象存在,那么 Map 中的 Thread 对象就永远不会被回收。ThreadLocal 的生命周期往往都比线程要长,所以这种设计方案很容易导致内存泄漏。而 Java 的实现中 Thread 持有 ThreadLocalMap,而且 ThreadLocalMap 里对 ThreadLocal 的引用还是弱引用,所以只要 Thread 对象可以被回收,那么 ThreadLocalMap 就能被回收。Java 的实现方案虽然看上去复杂一些,但是更安全。
ThreadLocal 与内存泄漏
但是如果在线程池中使用 ThreadLocal 可能会导致内存泄漏,原因是线程池中线程的存活时间太长,往往和程序都是同生共死的,这就意味着 Thread 持有的 ThreadLocalMap 一直都不会被回收,再加上 ThreadLocalMap 中的 Entry 对 ThreadLocal 是弱引用,所以只要 ThreadLocal 结束了自己的生命周期是可以被回收掉的。但是 Entry 中的 Value 却是被 Entry 强引用的,所以即便 Value 的生命周期结束了,Value 也是无法被回收的,从而导致内存泄漏。
我们可以通过 try{} finally{} 方案来手动释放资源。
ExecutorService es; |
Handler 的同步屏障机制
简介
Handler 加入了同步屏障机制,来实现异步消息优先执行的功能。
Handler 通过 MessageQueue.postSyncBarrier() 发送同步屏障,MessageQueue.removeSyncBarrier() 移除同步屏障。
同步屏障的作用可以理解成拦截同步消息的执行,主线程的 Looper 会一直循环调用 MessageQueue.next() 来取出队头的 Message 执行,当 Message 执行完后再去取下一个。当 next() 方法在取 Message 时发现队头是一个同步屏障的消息时,就会去遍历整个队列,只寻找设置了异步标志的消息,如果有找到异步消息,那么就取出这个异步消息来执行,否则就让 next() 方法陷入阻塞状态。如果 next() 方法陷入阻塞状态,那么主线程此时就是处于空闲状态的,不处理消息。总的来说就是队头是一个同步屏障的消息的话,那么在它后面的所有同步消息就都被拦截住了,直到这个同步屏障消息被移除出队列,否则主线程就一直不会去处理同步屏幕后面的同步消息。而所有消息默认都是同步消息,只有手动设置了异步标志,这个消息才会是异步消息。但是同步屏障消息只能由 Android 内部来发送,这个接口不提供给应用开发者使用。
Choreographer 与同步屏障机制
Choreographer 里所有跟 message 有关的代码,都设置了异步消息的标志,所以这些操作是不受到同步屏障影响的。这样做的原因可能就是为了尽可能保证在接收到屏幕刷新信号时,可以在第一时间执行遍历绘制 View 树的工作(doTraversal()),在绘制工作的时候,如果有其他同步消息都要等到 doTraversal() 之后来避免掉帧现象。
那么,有了同步屏障消息的控制就能保证每次一接收到屏幕刷新信号就第一时间处理遍历绘制 View 树的工作么?
答案是不一定的,因为同步屏障是在 scheduleTraversals() 方法被调用时才发送到消息队列里的,也就是说,只有当某个 View 发起了刷新请求时,在这个时刻后面的同步消息才会被拦截掉,而在 scheduleTraversals() 之前就发送到消息队列里的工作仍然会按顺序依次被取出来执行。
关于屏幕刷新机制可参考这篇文章。
如何监听应用的帧率?
可通过 Choreographer.getInstance().postFrameCallback() 来监听帧率情况:
public class FPSFrameCallback implements Choreographer.FrameCallback { |
在 Application 中注册 FPSFrameCallback:
Choreographer.getInstance().postFrameCallback(FPSFrameCallback(System.nanoTime())) |
Handler 中的锁
在不同的线程都可以使用 Handler 来发送消息,那么它是怎么保证线程安全的呢?
Handler 通过 Handler.sendMessage()、Handler.post() 等方法发送消息,会调到 MessageQueue.enqueueMessage() 方法:
// MessageQueue.java |
其内部通过 synchronized 关键字保证线程安全,同时 MessageQueue.next() 内部也会通过 synchronized 加锁,确保取的时候线程安全,同时插入也会加锁。 MessageQueue.next() 方法中的 synchronized 为 this 加锁,意思是为 MessageQueue 对象加锁。
关于锁的机制会在其他文章展开。(TODO)
面试题
Handler 是如何进行线程切换的?
原理很简单,线程间是共享资源的,子线程通过 Handler.sendMessage()、Handler.post() 等方法发送消息,然后通过 Looper.loop() 在消息队列中不断的循环检索消息,最后交给 Handler.dispatchMessage() 方法进行消息的分发处理。
Handler 为什么会导致内存泄漏?为什么其他的类没有出现内存泄漏的问题,比如 Adapter 中的 ViewHolder。
当在 Activity 中创建非静态的 Handler 类时,这个 Handler 为 Activity 的匿名内部类,当它调用 Activity 的方法时,Handler 是持有 Activity 的,导致 Activity 无法回收。
Adapter 中的 ViewHolder 没有内存泄漏的原因是因为 ViewHolder 的生命周期比 Adapter 短。但是 Handler 的生命周期可能比 Activity 的生命周期长,比如延时发送消息的情况。
如何在子线程中创建 Handler?
因为在子线程中是不存在 Looper 的,所以先要创建一个 Looper,也就是调用 Looper.prepare() 方法,并调用 Looper.loop() 方法,使 Looper 运转起来,这样子线程的 Handler 才能正常使用。
new Thread(new Runnable() { |
这里需要注意在所有事情处理完成后应该调用 quit() 方法来终止消息循环,否则这个子线程就会一直处于循环等待的状态,因此不需要的时候终止 Looper,调用 Looper.myLooper().quit()。
如何在主线程中访问网络?
在网络请求之前添加如下代码:
StrictMode.ThreadPolicy policy = new StrictMode.ThreadPolicy.Builder().permitNetwork().build(); |
StrictMode(严苛模式)Android2.3 引入,用于检测两大问题:ThreadPolicy(线程策略)和VmPolicy(VM策略),这里把严苛模式的网络检测关了,就可以在主线程中执行网络操作了,一般是不建议这么做的。关于严苛模式可以查看这里。
系统为什么不建议在子线程中访问 UI?
这是因为 Android 的 UI 控件不是线程安全的,如果在多线程中并发访问可能会导致UI控件处于不可预期的状态,那么为什么系统不对 UI 控件的访问加上锁机制呢?缺点有两个:
- 首先加上锁机制会让 UI 访问的逻辑变得复杂。
- 锁机制会降低 UI 访问的效率,因为锁机制会阻塞某些线程的执行。
子线程如何通知主线程更新 UI?
- 主线程中定义 Handler,子线程通过 mHandler 发送消息,主线程 Handler 的 handleMessage 更新 UI。
- 用 Activity 对象的 runOnUiThread 方法。
- 创建 Handler,传入
getMainLooper()。 View.post(Runnable r)。
Looper 死循环为什么不会导致应用卡死,会耗费大量资源吗?
Looper 并非简单地死循环,无消息时会休眠。Android 是基于消息处理机制的,用户的行为都在这个 Looper 循环中,我们在休眠时点击屏幕,便唤醒主线程继续进行工作。->
如何处理 Handler 使用不当造成的内存泄漏?
- 有延时消息,在界面关闭后及时移除 Message/Runnable,调用
handler.removeCallbacksAndMessages(null) - 内部类导致的内存泄漏改为静态内部类,并对上下文或者 Activity/Fragment 使用弱引用。
如果有个延时消息,当界面关闭时,该 Handler 中的消息还没有处理完毕,那么最终这个消息是怎么处理的?比如打开界面后延迟 10s 发送消息,关闭界面,最终在 Handler(匿名内部类创建的)的 handleMessage() 方法中还是会收到消息。因为会有一条 MessageQueue -> Message -> Handler -> Activity 的引用链,所以 Handler 不会被销毁,Activity 也不会被销毁。
丢帧的原因有哪些?
- 遍历绘制 View 树计算屏幕数据的时间超过了 16.6ms。
- 主线程一直在处理其他耗时的消息,导致遍历绘制 View 树的工作迟迟不能开始,从而超过了 16.6 ms 底层切换下一帧画面的时机。